
Replicating Midjourney Style References in Qwen Image Models
Diffusion Models and Style
One of the hardest parts of using diffusion models is trying to describe a visual aesthetic purely through words, some closed source models like Midjourney have tried to fix this by letting users refer to an “sref” code, which is a numeric style reference attached to an image, allowing users to attach a desired sref along with their text prompt to achieve a desired aesthetic. A great new paper called CoTyle has now brought that same functionality to an open source model, Qwen Image. In this post we’ll explore how CoTyle works and how we can even expand on the paper to allow users to submit images to the style codebook the paper implemented to get their own personal sref number codes for an open source model!
Let’s motivate our exploration with a real world challenge, imagine you wanted a text-to-image model to create a still life painting of fruit in the style of Yayoi Kusama. A major challenge is that Kusama’s most popular artwork on the internet are often images of polka-dot sculptures, meaning text-to-image models have vastly overfit her name and style to only a specific subset of her work. In this particular case, we actually have real examples of what her still life paintings of fruit looked like from the 1980s.
Real examples of fruit still life paintings from Yayoi Kusama from the 1980s:




Unfortunately, if we simply try to replicate her style with a simple text prompt, the results across even the latest text-to-image models fail to capture her true style for these paintings.
Attempts by Z-Image Turbo , Flux 2, Nano Banana Pro, Qwen Image to re-create: “A still life painting of watermelons in the style of Yayoi Kusama”




What we’ll need is a way to provide her existing artwork as a visual style reference. The CoTyle paper presents an architecture that allows for the creation of a style codebook, which we can then utilize to provide a reference image and extract the closest numeric style reference. Let’s explore how the paper works!
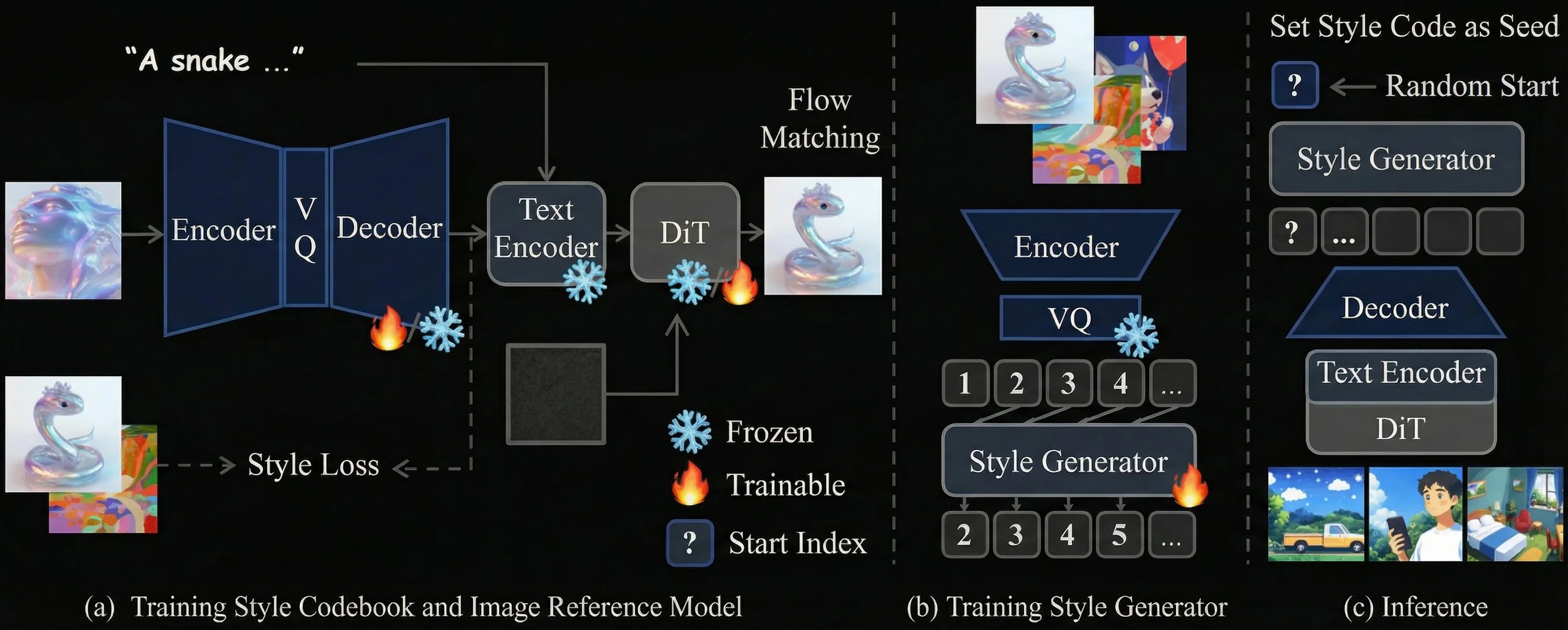
CoTyle Training Architecture
CoTyle builds a small stack of models around a text‑to‑image diffusion transformer. The base is a discrete style codebook that is trained to capture style while discarding content. Using a ViT encoder, the authors fed in pairs of images (some with similar styles but different content, and others with that were far apart in style), and optimizes a contrastive loss that pulls same‑style pairs together and pushes different styles apart.
A small “reconstruction” loss keeps each quantized vector close to its original ViT feature, so the style tokens still live in a space the rest of the system understands. Standard VQ losses stop the codebook from collapsing and encourage all tokens to be used. After this training, any style image becomes a grid of discrete indices—a compact summary of how the image looks (a style), not what it shows (the content).
Here is one of the key insights of the paper: those indices are then fed into a text‑to‑image DiT (Qwen‑Image) through the text branch, not as a second image. If you inject style as another visual input, the model mostly copies colors and rough lighting. If you inject it via the text encoder, the style embedding acts more like a high‑level instruction about drawing style—linework, framing, “paper‑cut” silhouettes—while the normal text prompt still controls the subject. During training, one image in a pair provides the style, the other serves as the target, and rectified flow matching teaches the DiT to render the target prompt in the source style. The result is a very capable image‑conditioned stylization model.
The distinctive step is to generate styles directly from numbers, without any reference image. You can even play around with it for free on their Hugging Face Space for CoTyle.
After quantization, each style image is just a sequence of discrete indices, so the authors train an autoregressive transformer (essentially a small LLM) to model these sequences with next‑token prediction. At inference time, a user‑provided integer seeds the sampling process: the seed fixes the first index, the transformer autoregressively produces the remaining indices, and this sequence is mapped back through the codebook to a synthetic style embedding. That embedding conditions the diffusion model alongside the text prompt, so the same integer reliably recreates the same style—easy to archive, easy to share.
We can then extend the CoTyle GitHub codebase to support a more natural visual workflow: start from an image, automatically recover its style, and then reuse that style on new content. Conceptually, the process works like this: You feed in a reference image whose look you care about (we’ll use the real world Kusama still life paintings) and CoTyle first runs it through its vision backbone and discrete style codebook. That codebook “snaps” the continuous visual features into a sequence of discrete style tokens, which together act as a compact fingerprint of the image’s aesthetic. Instead of providing a numeric style code, you simply tell the pipeline, “use whatever style you just extracted from this image,” and then supply a text prompt that describes the content you want (“a bowl of watermelons on a table,” for example).
The diffusion model then generates a new image by combining the prompt with those automatically derived style tokens. In practice, this gives you a very direct interaction pattern: show the system a painting you like, let it infer the nearest style code under the hood, and immediately reuse that style on arbitrary new scenes. Here is the result of passing in a single reference image and asking for a still life painting of watermelon:

Result from Qwen using a style reference based off a true Kusama still life.
The code for this can be found at: https://gist.github.com/jmportilla-tio-magic/b44996d642a3288f5b9ad2e9e3ab2e8a
Hopefully you can use our code to continue exploring and creating new images based on your favorite style aesthetics! Thanks for reading!